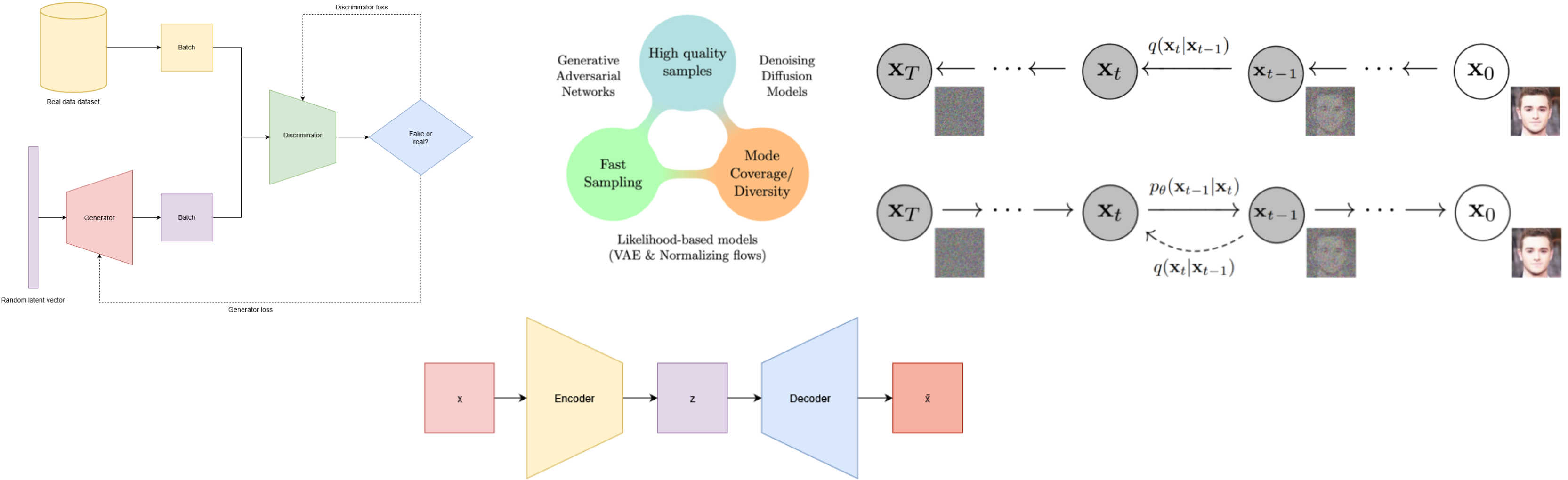
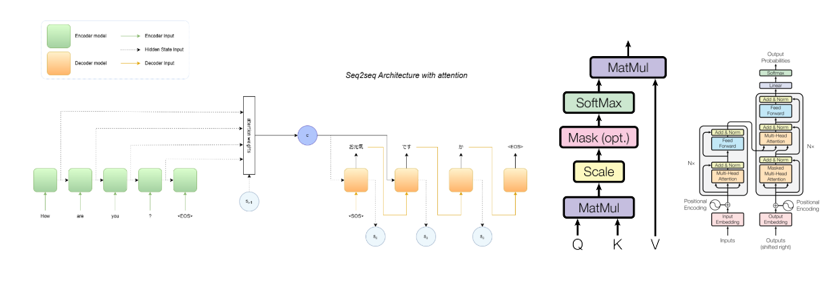
Hi, I’m Oriol Alàs Cercós, an AI Engineer and Researcher 🔬 with a passion for Machine Learning, Computer Vision, and Large Language Models (LLMs).
This blog is a personal notebook where I document projects, experiments, and ideas related to artificial intelligence, machine learning, and applied research.