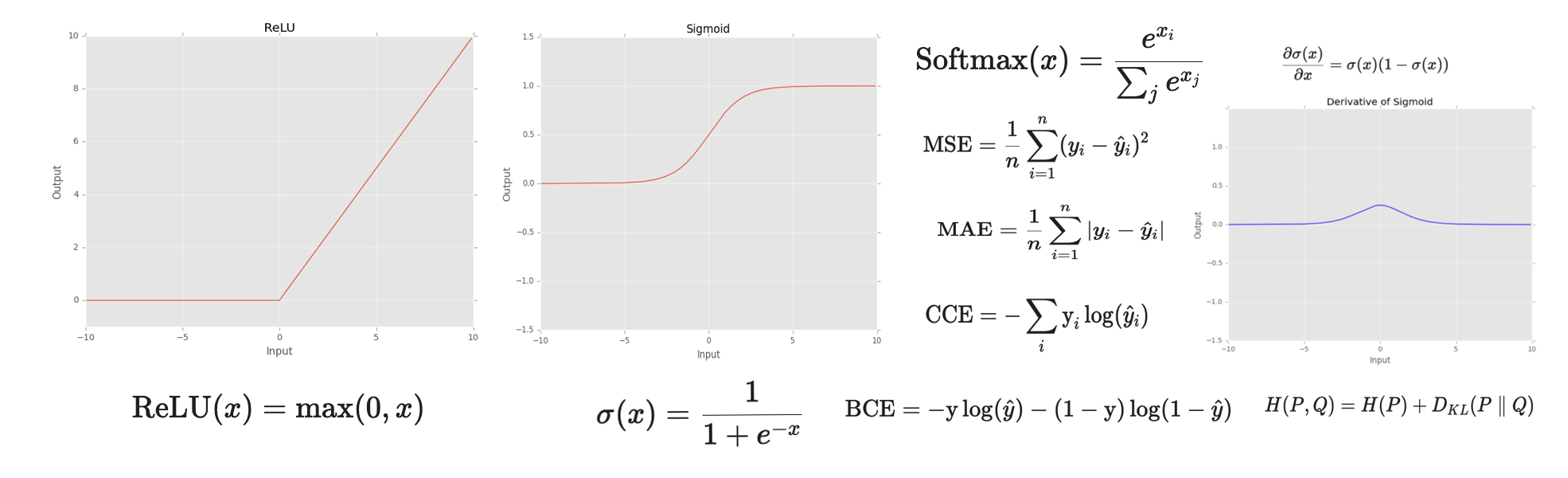
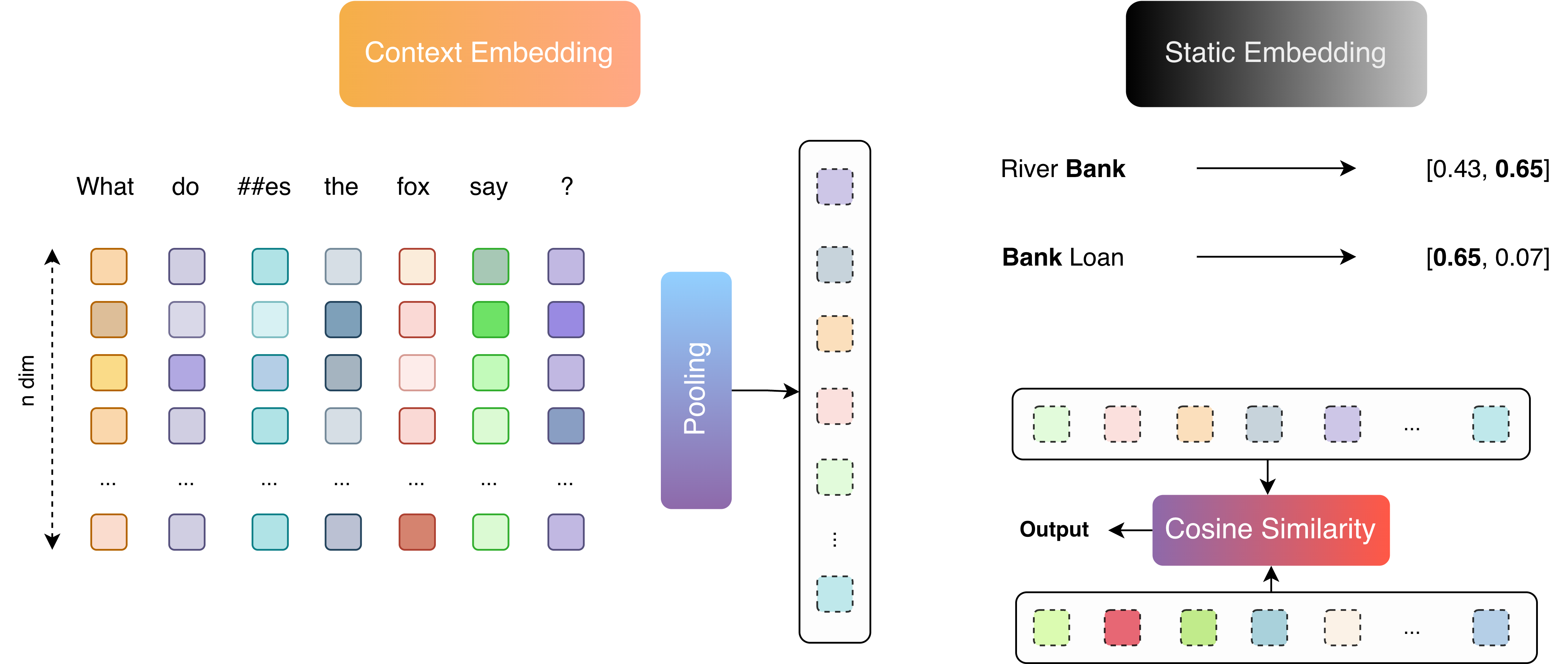
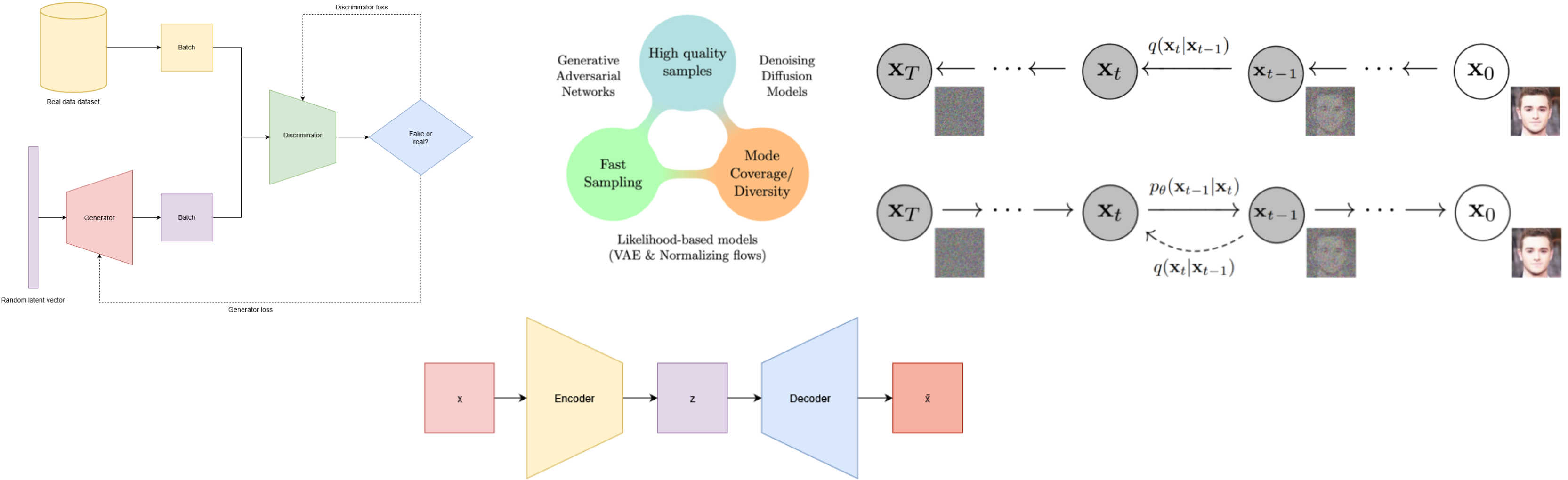
Embedding models are foundational in modern NLP, turning raw text into numerical vectors that preserve semantic significance. These representations power everything from semantic search to Retrieval-Augmented Generation or Prompt Engineering for LLM Agents. With growing demand for domain-specific applications, understanding which is the best fit for your system is more important than ever.
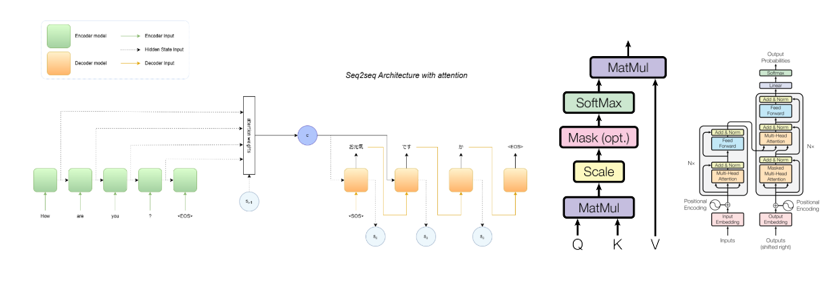
Introduction In modern NLP, a text embedding is a vector that represents a piece of text in a mathematical space. The magic of embeddings is that they encode semantic meaning: texts with similar meaning end up with vectors that are close together. For example, an embedding model might place “How to change a tier” near “Steps to fix a flat tire” in its vector space, even though the wording is different. This property makes embedding models incredibly useful for tasks like search, clustering or recommendation, where we care about semantic similarity rather than exact keyword matches. By converting text into vectors, embedding models allow computers to measure meaning and relevance via distances in vector space.
...