Transformers have demonstrated excellent capabilities and they overcome challenges such NLP, Text-To-Image Generation or Image Completion with large datasets, great model size and enough compute. Talking about transformers nowadays is as casual as talking about CNNs, MLPs or Linear Regressions. Why not take a glance through this state-of-the-art architecture?
In this post, we’ll introduce the Sequence-to-Sequence (Seq2Seq) paradigm, explore the attention mechanism, and provide a detailed, step-by-step explanation of the components that make up transformer architectures.
Sequence-to-sequence paradigm
Seq2Seq was initially introduced in Recurrent Neural Networks (RNN) and later enhaced by Long Short-Term Memory (LSTM) networks. This architecture splits the task into two primary components:
- Encoder. It processes and compresses the input sequence into a fixed-length vector, commonly referred to as the context vector or hidden state.
- Decoder. Sequentially generates the target output using the information encoded in the context vector.
In essence, we encode the input language and decode the language of translation. For example, English uses a Subject-Verb-Object (SVO) order, while Japanese goes with Subject-Object-Verb (SOV) and often skips the subject altogether.This flexibility lets Seq2Seq models adapt to these quirks and do a great job of capturing the meaning and flow of translations.
, updating its hidden state with each step. Upon encountering the End of Sequence (`<EOS>`) token, the final hidden state is passed to the decoder model. The decoder then generates the output sequence (`お元気ですか`) token by token, starting with the Start of Sequence (`<SOS>`) token and continuing until the End of Sequence (`EOS`) token is reached.")
How are you?), updating its hidden state with each step. Upon encountering the End of Sequence (<EOS>) token, the final hidden state is passed to the decoder model. The decoder then generates the output sequence (お元気ですか) token by token, starting with the Start of Sequence (<SOS>) token and continuing until the End of Sequence (EOS) token is reached.
Sequence-to-sequence with attention
What are the next steps before talking about transformers? You may already know that transformers’ basis is the attention mechanism. But, what is attention?
One of the main challenges with Seq2Seq models is the fixed-length context vector passed from the encoder to the decoder. Since its fixed-length, the resulting context vector might have more information about the last tokens than the first ones. Hence, the decoder cannot focus on specific parts of the input sentence. For longer sentences, this bottleneck can result in loss of information, making translations less accurate or meaningful.
Attention tries to sort out this issue by allowing the decoder to focus on specific parts of the input sequence at each step of the generation process. Instead of relying only on the resulting context vector, the attention mechanism calculates a weighted combination of all encoder hidden states. This ensures that the decoder has access to the most relevant information.
Attention is a mechanism that allows a model to focus on the most relevant parts of an input when making a prediction. We can say that it calculates, from a token, the weights (importance) of the other tokens on the fly.
, updating its hidden state with each step. The hidden states are stored at each encoding step until encountering the End of Sequence token. The decoder then generates the output sequence (`お元気ですか`) token by token, starting with the Start of Sequence (`<SOS>`) token and continuing until the End of Sequence (`EOS`) token is reached. The hidden state passed to the decoder is built using the attention mechanism at each step using the hidden states of the encoder model and the previous hidden state of the decoder model.")
How are you?), updating its hidden state with each step. The hidden states are stored at each encoding step until encountering the End of Sequence token. The decoder then generates the output sequence (お元気ですか) token by token, starting with the Start of Sequence (<SOS>) token and continuing until the End of Sequence (EOS) token is reached. The hidden state passed to the decoder is built using the attention mechanism at each step using the hidden states of the encoder model and the previous hidden state of the decoder model.
- Alignment. At each decoding step, the attention mechanism calculates a score to determine the relevance of each encoder hidden state to the current decoder state. There are a great amount of alignments but the most popular are Bahdanau (Additive Attention) and Scaled-Dot Product Attention.
- Weighting. Theses scores are normalized using softmax to generate a set of attention weights.
- Context vector. The attention weights are used to compute a weighted sum of the encoder hidden states, producing a context vector specific to the current output generation.
- Output Generation. The context vector is then combined with the decoder’s state to generate the next token.
The attention mechanism is useful in tasks like translation, where alignment between input and output sequences is important. Also, the selective focus makes the model more interpretable, since it can provide insights into which parts of the input the model considers relevant, offering a form of explainability.
Nevertheless, the attention mechanism requires computing attention scores between each decoder step and all encoder outputs and for long input sentences, this results in a large number of computations, scaling computation time and memory consumption.
Finally, it’s important to note that the decoder in Seq2Seq architecture operates in an autoregressive manner, generating tokens one at a time. The sequential process limits parallelization during decoding, resulting into slower inference times compared to non-autoregressive models, which can generate multiple tokens simultaneously.
You may find more information in the tag seq2seq.
Transformer architecture
Transformers [1] emerged as a way to built encoder-decoder architectures to solve machine translation problems. While RNNs and LSTMs use recurrent steps and can suffer more from vanishing gradients and limited parallelization, transformers bypass this by processing sequences in parallel.
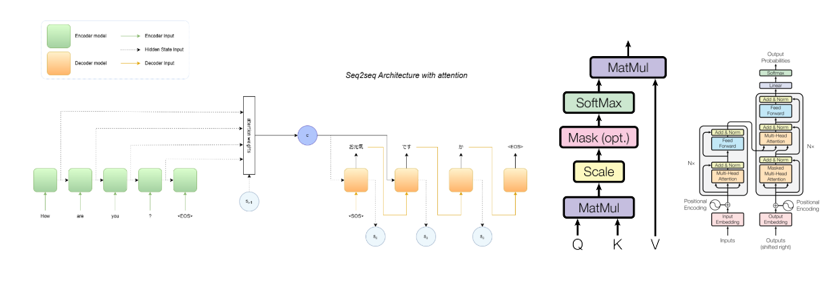
The transformer neural network is composed by an encoder-decoder architecture much like RNN. However, the difference is that the input sequence can be passed in parallel by passing also the positional encoder zipped with, as the input might have different meaning depending on its position.

Fig. 3. Transformer model architecture Attention is all you need.
The input and the positional encoding are passed into the encoder block. The job of the encoder is to map all input sequence into abstract continuous representation that holds the learned information for that entire sequence. The encoder block has \(N\) identical encoder layers. The main objective of the encode is to capture the attention between tokens in both ways, also called self-attention or bidirectional attention. This means that in this part we attempt to capture each token’s relevant parts from all the tokens of the sentence (although they are after the token). Hence, the encoder part is non-autorregressive.
Regarding the decoder block, it has several similarities with the encoder block. They both have \(N\) identical layers and a position encoding at first of all. However, multi-head attention layers of the decoder block have different job compared to the encoder. The decoder is auto-regressive and it takes the previous outputs from itself and the encoder output vector as inputs. This is because the encoder can use all the elements of the input sentence but the decoder can only use the previous elements of the sentence. The attention captured in decoder blocks is called casual attention.
Positional Encoding
Positional encoding is the process of producing a vector that gives context based on position of the element in a sentence, so we will end up with a matrix of encoded positions. We could have only uni-dimensional vector of natural numbers like \([1, 2, ..., n]\). But one of the reasons we want positional encoding is not only feed the positions but their relationships. Therefore, they came up with a way of capture both absolute and relative positions with smooth representation of the position information (taking into account that the difference between 1000 and 1001 is “smaller” than the difference between 1 and 2) and providing better high-dimensional contextual information.
\[ PE_{(pos, 2i)} = \sin\left(\frac{pos}{n^{\frac{2i}{d_{model}}}}\right)\]\[PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{n^{\frac{2i}{d_{model}}}}\right)\]where
- \(pos\) is the position index of the token
- \(i\) is the index of the encoding dimension
- \(d_{model}\) is the dimensionality of the model’s embedding space
- \(n\) is the base of the frequency scaling factor, being set up to \(10000\)
For every odd step, they create the vector using the cosine function while for every even time step, they use the sine function. These functions have linear properties the model can easily learn to attend to when adding these vectors to their corresponding vector. The result of these functions will be concatenated to the input embedding vector.
The most difficult part to understand from this formula might be the denominator. This part ensures that different frequency scales across dimensions. While lower dimensions of the positional encoding captures higher frequency variations, higher dimensions capture lower frequency variations, allowing them to encode larger positional distances smoothly. The following figure might help to understand the magic of it.

import numpy as np
import matplotlib.pyplot as plt
def plot_sinus(k, ax, d=512, n=10000):
x = np.arange(0, 200, 1)
denominator = np.power(n, 2*x/d)
y = np.sin(k/denominator)
ax.plot(x, y)
ax.set_title('k = ' + str(k))
ax.set_xlabel("Dimension")
ax.set_ylim([-1, 1])
ax.set_xlim([0, 200])
fig, axs = plt.subplots(1, 4, figsize=(16, 4))
fig.tight_layout()
for i, ax in enumerate(axs.flat):
plot_sinus(i*4, ax)
Scaled Dot-Product Attention
There are several attention mechanisms: additive, content-base, badhanau [2]… Transformers introduced a new mechanisme called Scaled Dot-Product Attention. An attention function can operate using queries (Q), keys (K) and values (V).

Fig. 5. Scaled Dot-Product Attention Attention is all you need.
The query is a vector related with what we encode, the key is a vector related with what we use as input to output and the value is the learned vector as a result of calculations but related with the input. In other words, the query represents what we are looking for, the key represents possible matches in the input and the value represents the actual information associated with each key.
\[Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}}) \cdot V \]where \(d_k\) is the dimensionality of the key vectors. The idea is practically the same: the result is a weighted sum of values, where more relevant elements contribute more to the output.
Multi-Head Attention Layer
To give the encoder model more representation power of the self-attention, they created the Multi-Head Attention Layer. Instead of computing a single attention function, the Scaled Dot-Product Attention is splitted into several blocks called heads, each running in parallel. Each head independently computes attention and is then concatenated to form the final output.

Fig. 6. Multi-Head Attention Layer Attention is all you need.
The input of each head is first fed into three distinct fully connected layers to create the query, key and value vectors. These transformations allow the network to learn different types of relationships between tokens. The idea is that the attention block must map the query against a set of keys to then present the best attention, which will be embedded to the values.

Fig. 7. Example of Multi-Head Attention Layer mechanism.
After computing attention in each head, the results are concatenated and passed through a linear projection layer. This ensures that the output has the same dimensionality as the input, allowing for seamless integration with subsequent layers.
Masked Multi-Head Attention block
The encoder block has two sub-layers: a multi-head attention layer and a feed forward layer. Both sub-layers have a residual connection and a layer normalization next to their output vector. The residual connections helps the network to train by allowing gradients to flow directly through the network while the normalization is used to stabilize the network.
The decoder block consists of three sub-layers: two multi-head attention layer and one feed-forward layer. The first multi-head attention layer in the decoder is masked to prevent it from attending to future tokens. This is achieved by applying a mask to the attention score matrix before computing softmax, ensuring that predictions for a given token do not depend on future tokens.
In the second multi-head attention layer, the queries and keys come from the encoder’s output, while the values are derived from the output of the first attention layer in the decoder. This mechanism enables the decoder to integrate information from the encoder while maintaining the structure of previously generated tokens. The final output is then processed by a feed-forward layer before being passed to a linear layer and a softmax function, which converts it into a probability distribution over possible output tokens.
Cross-Attention
The interaction between the encoder and decoder is facilitated by cross-attention. In the second multi-head attention layer of the decoder, the queries originate from the decoder’s previous output, while the keys and values come from the encoder’s output. This allows the decoder to focus on relevant parts of the input sequence when generating each token in the output. Cross-attention is essential for tasks such as machine translation, where the output sequence depends heavily on the input sequence.
References
[1] Ashish Vaswani, et al. Attention is all you need, NIPS 2017
[2] Bahdanau et al. Neural Machine Translation by Jointly Learning to Align and Translate, ICLR 2015
Citation
Alàs Cercós, Oriol. (Feb 2025). Introduction to Attention Mechanism and Transformers. https://oriolac.github.io/posts/2024-10-29-attention/.
@article{alas2025,
title = "Introduction to Attention Mechanism and Transformers.",
author = "Alàs Cercós, Oriol",
journal = "oriolac.github.io",
year = "2025",
month = "February",
url = "https://oriolac.github.io/posts/2024-10-29-attention/"
}