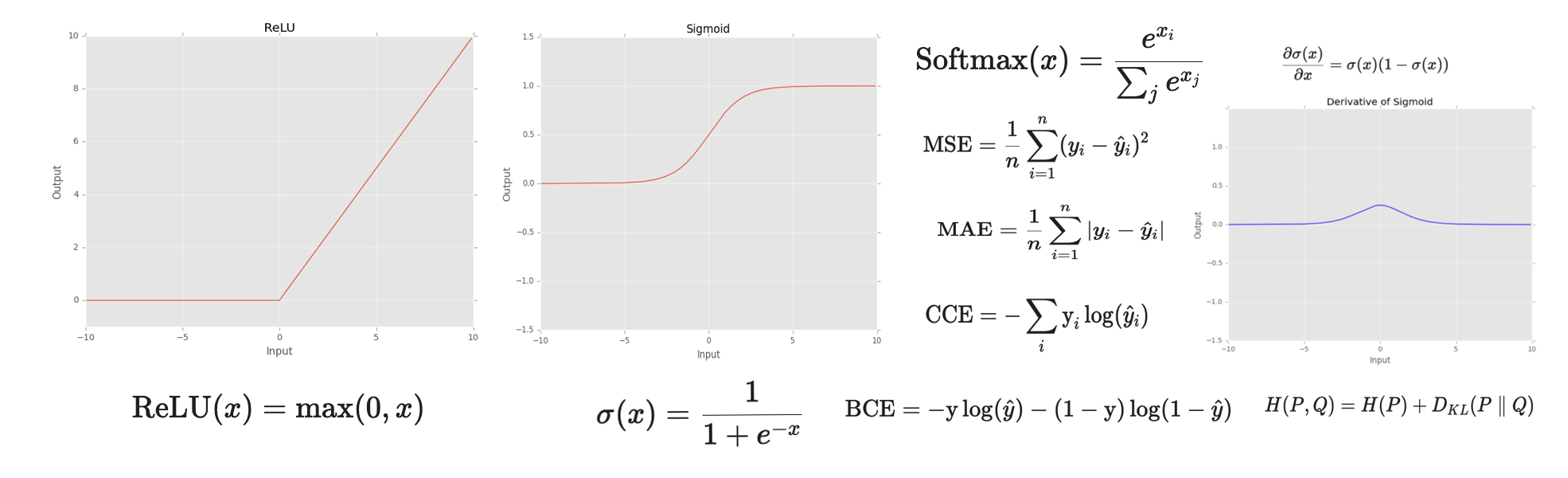
Reviewing YOLO: You Only Look Once
Object detection is one of the most popular tasks in computer vision, since it can be applied to a wide range of applications: robotics, autonomous driving or fault detection. In this post, we will try to give a brief overview of the YOLO algorithm and the components that make it work. To do that, I have classified the main components of the algorithm into three categories: Characteristics based on the model architecture, how YOLO-based models improved the performance by using a new architecture and which are the improvements made. Strategies based on the model training, such as the function loss or data augmentation. Methods for post-processing the output of the model, such as the non-maximum suppression (NMS) and the confidence threshold. Two-stage vs One-stage Detectors Before YOLO, SoTA detectors were based on a two-stage detector: the first stage is used to detect the bounding boxes, and the second stage is used to classify the bounding boxes. This kind of model is called region-based detectors, because they need the region to then run the classification. ...